










Unified API, Infinite Model
Free to switch all models with one access. Fully compatible with the OpenAI interface specification, only the model name needs to be changed. Function Calling and JSON Mode are supported.
There is no need to adapt to multiple vendor SDKs and maintain complex routing. It is fully compatible with the standard interface specification, and can be connected to the most cutting-edge model in the market with zero transformation in 5 minutes.
Solve the three pain points of multi-source access difficulty, manufacturer instability and high cost from the root, so that you can focus on the innovation of core applications.
Free to switch all models with one access. Fully compatible with the OpenAI interface specification, only the model name needs to be changed. Function Calling and JSON Mode are supported.
According to the real-time node delay and success rate. When there are very few manufacturer fluctuations, the hot switch to the standby model is extremely fast and smooth, and the core experience is guaranteed.
Self-built global multi-regional distribution network, with request circuit breaker, exponential retry and intelligent current limiting strategy. Deliver 99.99% core Netflow SLAS.
Integrate the semantic precision cache architecture, and return the results directly in the face of high-frequency similar requests. No need to call large models, saving 40-70% of the cost per million times.
Minimalist configuration. Provide SDK and native HTTP direct connection support. Out of the box, Playground supports instant debugging, parameter monitoring, and streaming results.
Have full control over your data. Includes advanced audit logs, sub-account role access authentication, and the ability to lock data routing physical areas for compliance needs.
The ability to directly simulate extreme concurrency online or explore the differences between models of various manufacturers without building an environment.
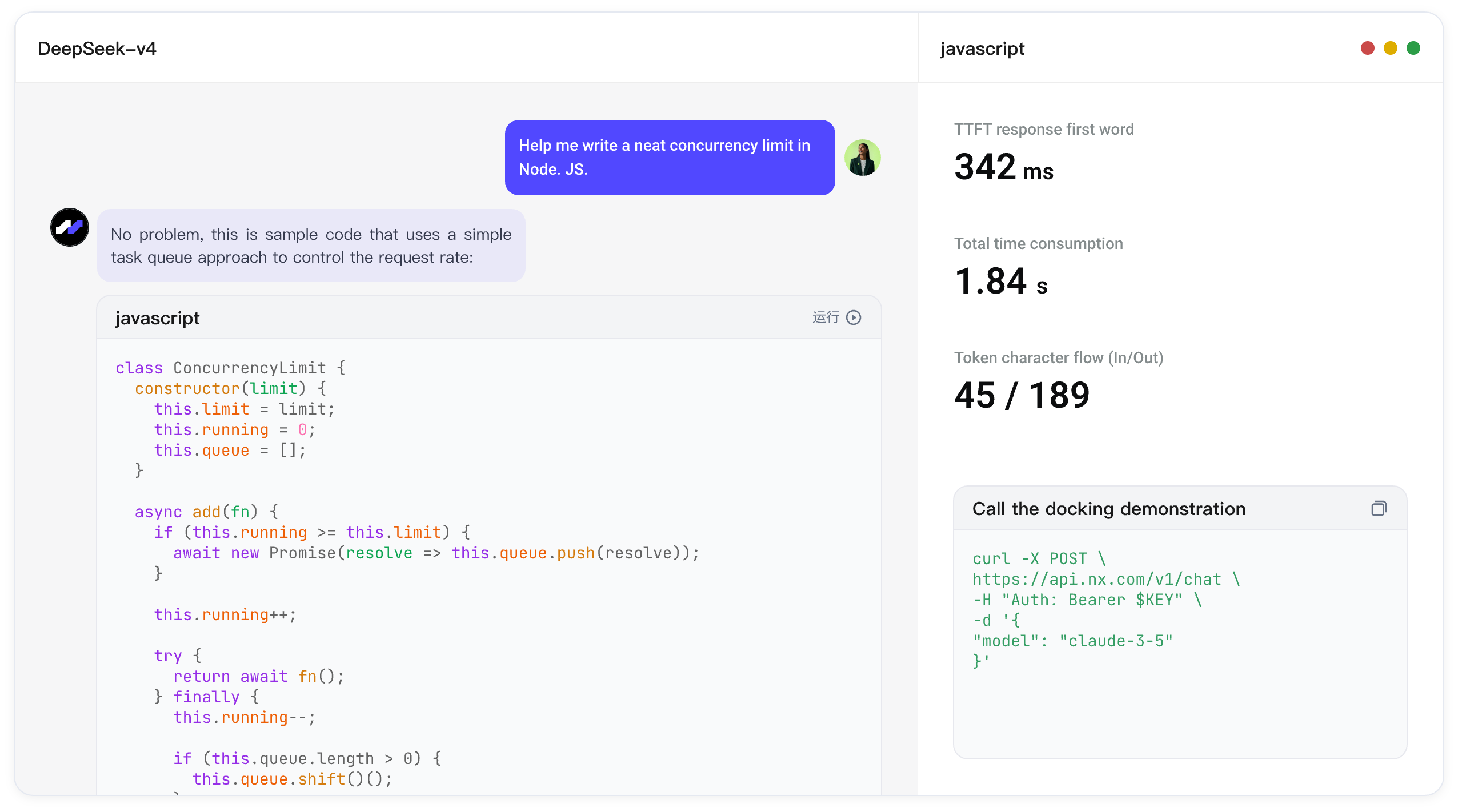
Relying on global high-speed edge node scheduling, create a reliable and low-latency interactive experience of large language model.
Based on the intelligent algorithm, the entrance is allocated nearby to extremely shorten the delay of physical long connection.
The forwarding link is optimized in the underlying concurrency language, with special network acceleration for streaming replies.
Adaptively intercepts homogeneous requests and performs extremely well in specific high-frequency scenarios.
From a very small number of requests to an instant million traffic peak, the back-end provides senseless thermal expansion.
Transparently answer every question about interface switching and stability.

The first advantage is the reduction of development intervention time, which can effectively reduce the dirty work of abnormal polling maintenance between manufacturers by docking single authentication and common API. At the same time, it can avoid many uncertain network disconnection and abnormal invoice obstacles, so that you can completely avoid the risk of payment and use the automatic peak clipping function in the back cost to bring real savings.